

There are multiple things which can get corrupted and I will be looking in details on the simple one in this article – when page in clustered key index is corrupted. It is worse compared to having data corrupted in secondary indexes, in which case simple OPTIMIZE TABLE could be enough to rebuild it, but it is much better compared to table dictionary corruption when it may be much harder to recover the table.
In this example I actually went ahead and manually edited test.ibd file replacing few bytes so corruption is mild.
First I should note CHECK TABLE in INNODB is pretty useless. For my manually corrupted table I am getting:
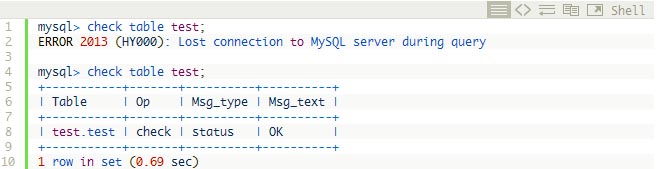
First run is check table in normal operation mode – in which case Innodb simply crashes if there is checksum error (even if we’re running CHECK operation). In second case I’m running with innodb_force_recovery=1 and as you can see even though I get the message in the log file about checksum failing CHECK TABLE says table is OK. This means You Can’t Trust CHECK TABLE in Innodb to be sure your tables are good.
In this simple corruption was only in the data portion of pages so once you started Innodb with innodb_force_recovery=1 you can do the following:
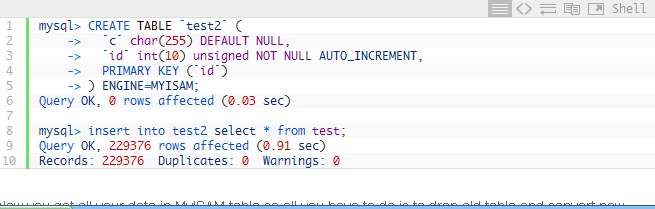
Now you got all your data in MyISAM table so all you have to do is to drop old table and convert new table back to Innodb after restarting without innodb_force_recovery option. You can also rename the old table in case you will need to look into it more later. Another alternative is to dump table with MySQLDump and load it back. It is all pretty much the same stuff. I’m using MyISAM table for the reason you’ll see later.
You may think why do not you simply rebuild table by using OPTIMIZE TABLE ? This is because Running in innodb_force_recovery mode Innodb becomes read only for data operations and so you can’t insert or delete any data (though you can create or drop Innodb tables):
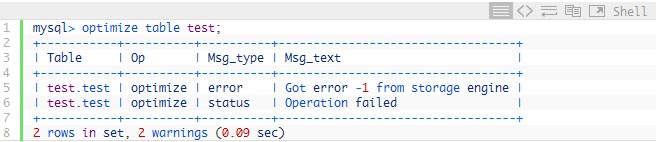
That was easy, right ?
I also thought so, so I went ahead and edited test.ibd a little more wiping one of the page headers completely. Now CHECK TABLE would crash even with innodb_force_recovery=1
080704 0:22:53 InnoDB: Assertion failure in thread 1158060352 in file btr/btr0btr.c line 3235
InnoDB: Failing assertion: page_get_n_recs(page) > 0 || (level == 0 && page_get_page_no(page) == dict_index_get_page(index))
InnoDB: We intentionally generate a memory trap.
InnoDB: Submit a detailed bug report to http://bugs.mysql.com.
InnoDB: If you get repeated assertion failures or crashes, even
If you get such assertion failures most likely higher innodb_force_recovery values would not help you – they are helpful in case there is corruption in various system areas but they can’t really change anything in a way Innodb processes page data.The next comes trial and error approach:

You may think will will scan the table until first corrupted row and get result in MyISAM table ? Unfortunately test2 ended up to be empty after the run. At the same time I saw some data could be selected. The problem is there is some buffering taking place and as MySQL crashes it does not store all data it could recover to MyISAM table.
Using series of queries with LIMIT can be handly if you recover manually:
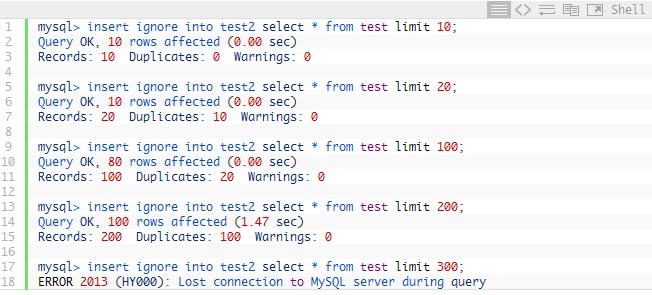
As you can see I can get rows from the table in the new one until we finally touch the row which crashes MySQL. In this case we can expect this is the row between 200 and 300 and we can do bunch of similar statements to find exact number doing “binary search”
Note even if you do not use MyISAM table but fetch data to the script instead make sure to use LIMIT or PK Rangers when MySQL crashes you will not get all data in the network packet you potentially could get due to buffering.
So now we found there is corrupted data in the table and we need to somehow skip over it. To do it we would need to find max PK which could be recovered and try some higher values
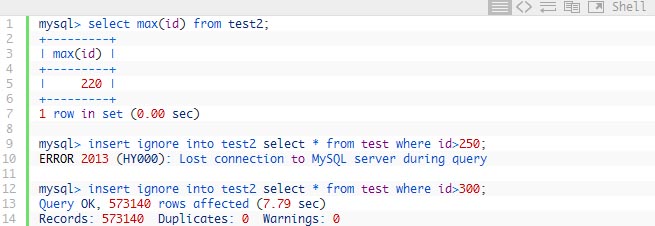
So we tried to skip 30 rows and it was too little while skipping 80 rows was OK. Again using binary search you can find out how many rows do you need to skip exactly to recover as much data as possible. Row size can be good help to you. In this case we have about 280 bytes per row so we get about 50 rows per page so not a big surprise 30 rows was not enough – typically if page directory is corrupted you would need to skip at least whole page. If page is corrupted at higher level in BTREE you may need to skip a lot of pages (whole subtree) to use this recovery method.
It is also well possible you will need to skip over few bad pages rather than one as in this example.
Another hint – you may want to CHECK your MyISAM table you use for recovery after MySQL crashes to make sure indexes are not corrupted.
So we looked at how to get your data back from simple Innodb Table Corruption. In more complex cases you may need to use higher innodb_force_recovery modes to block purging activity, insert buffer merge or recovery from transactional logs all together. Though the lower recovery mode you can run your recovery process with better data you’re likely to get.
In some cases such as if data dictionary or “root page” for clustered index is corrupted this method will not work well – in this case you may wish to use Innodb Recovery Toolkit which is also helpful in cases you’ve want to recover deleted rows or dropped table.
I should also mention at Percona we offer assistance in MySQL Recovery, including recovery from Innodb corruptions and deleted data.
Reference: https://www.percona.com/blog/2008/07/04/recovering-innodb-table-corruption/

