- Home
- About Us
- Recovery Services Individual RecoveryEnterprise RecoveryAdditional Recovery
- Software
- Testimonials
- Locations

Practical RAID 5 Recovery and XOR Mathematics in NTFS 5 (Part 2)
The last installment of this particular blog offered the basics of RAID 5 recovery technology and used a very simple truth table to illustrate the four (4) states of XOR mathematics. This week we will dig a little deeper into the technology and hopefully offer a clearer understanding of how the normal end user can in fact do RAID 5 recovery.
Once again, XOR mathematics offers four actions that work on a bitwise truth table. This truth table when used properly can in fact help one to not only recover their lost RAID data but find out critical facts like, drive order, stripe size, offset calculations, and RAID 5 symmetry. Let’s first take a look at what XOR math will do on actual live data. In order to do that, we must understand how data is stored on the computer in its most primitive state and how viewing that data in a certain way offers us a method for recovery.
We are going to start with a simple ASCII table which defines certain characters in an eight bit environment. Eight bit of course meaning the size of the data type. So each character has its own eight bit value and can be illustrated in several ways. As an example, let’s take the letter ‘A’. In the ACSII table the letter ‘A’ is represented by the decimal number 65. In binary, displaying all bits, the letter ‘A’ is represented by 01000001. Let’s now take the letter ‘Z’ and its ASCII table representation which is signified by the decimal number 90. The ‘Z’ in binary is expressed as 01011010. So, to explain this further, when the computer sees the number 65 it translates it into an ‘A’, and when it sees a 90, it translates that into a ‘Z’.
Now that we have the binary representation of the letter ‘A’, and the letter ‘Z’, let’s perform XOR operations on all eight bits and see what happens. Please refer to the previous blog on the XOR operation to see how the result was achieved.
Data recovery from RAID-0
When we received two Samsung 160Gb SATA hard drives in a RAID 0 configuration from an SQL server, visual examinations of the drives showed extensive platter damage to drive one in the array. After further examination in the clean room, it was apparent that the head assembly on drive one had crashed and there was extensive scratching to the platters. RAID 0 (striped disks) distributes data across several disks in a way that gives improved speed and no lost capacity and as this array has no actual redundancy, data will be lost if any one disk fails.
A ‘head crash’ had occurred and this 'impacted' the rotating platter surface. The head normally rides on a thin film of moving air entrapped at the surface of the platter. A shock to the working hard disk, or even a tiny particle of dirt or other debris had caused the head to bounce against the disk, destroying the thin magnetic coating on the disk. Since most modern drives spin at rates between 7,200 and 15,000 rpm, the damage caused to the magnetic coating was extensive. The data stored in the media that has been scraped off the platter is of course unrecoverable, and because of the way that data is stored in RAID 0, this data may be whole files or parts of many files.
The second drive was found to be healthy. Drive one was mechanically repaired using donor parts from the second drive. Drive two was healthy and was 'imaged' before being used as a donor. The extensive scratching to the media surface on drive one, only allowed us to gain a maximum 80% image. Once all the drives were imaged, including all the “white” areas (previously deleted or overwritten data), the RAID parameters, such as start sector, drive order, block size and direction of rotation were analyzed to determine the correct values. We then attempted to create a single copy of the reconstructed RAID in a virtual image file (.img).
Making Virtual Server Recovery-In-Place Viable
Backup technology for virtualized environments has become increasingly more advanced. Many organizations have implemented backup applications which are specifically designed to efficiently backup data in a virtualized environment without causing any disruption to application performance. In addition, some backup applications, like Veeam, now allow for data residing on a disk based backup target to be used as a boot device to support instant VM recoveries.
Boot From Backup
Generically referred to as “recovery-in-place”, this feature gives administrators the option to point a VM to the backup data residing on a disk partition (typically a backup appliance) so that a failed VM can be more quickly recovered. The idea is to use the backup data as a temporary boot area until a full data restore can be completed on to a primary storage resource.
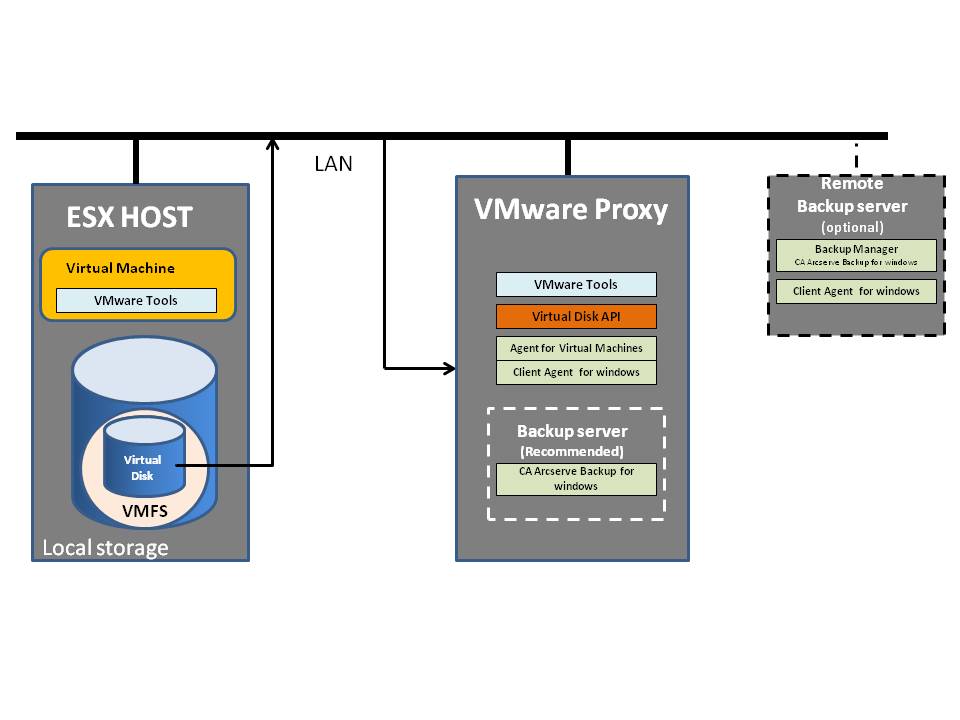
VMware - Virtual Disk Transport Methods
Virtual Disk Transport Methods
This document explains transport methods applicable for ARCserve version 15 and 16 using VDDK.
VMware supports file-based or image-level backups of virtual machines hosted on an ESX/ESXi host with SAN or iSCSI storage. Virtual machines can read data directly from shared VMFS LUNs, so backups are very efficient and do not put significant load on production ESX/ESXi hosts or the virtual network.
VDDK 5.0 release makes it possible to integrate storage-related applications, including backup, using an API rather than a command-line interface. VMware has developed back-ends that enable efficient access to data stored on ESX/ESXi clusters. Third party developers like CA can access these data paths (called advanced transports) through the virtual disk library. Advanced transports provide the most efficient transport method available, to help maximize application performance.
CA ARCserve supports transport methods discussed below: LAN (NBD/NBDSSL), SAN, and HotAdd.
LAN (NBD) Transport Mode
When no other transport mode is available, storage applications like Ca ARCserve backup can use LAN transport for data access, either NBD (network block device) or NBDSSL (encrypted). NBD is a Linux-style kernel module that treats storage on a remote host as a block device. NBDSSL uses SSL to encrypt all data passed over the TCP/IP connection. The NBD transport method is built into the virtual disk library, and is always available.
LAN (NBD) Transport Mode for Virtual Disk
rebuild_heaps - rebuild all fragmented heaps
Overview
Forwarded records can be bad for performance, but few are actually doing anything about it.
Lots of free space on your pages means more pages to scan, bigger backups etc.
Both forwarded records and free space on pages can be considered a type of fragmentation for a heap. This stored procedure rebuilds all fragmented heaps on a SQL Server.
Here are a couple of blog posts on the topic:
Knowing about 'Forwarded Records' can help diagnose hard to find performance issues(http://blogs.msdn.com/b/mssqlisv/archive/2006/12/01/knowing-about-forwarded-records-can-help-diagnose-hard-to-find-performance-issues.aspx)
Geek City: What's Worse Than a Table Scan?(http://sqlblog.com/blogs/kalen_delaney/archive/2008/05/25/whats-worse-than-a-table-scan.aspx)
The table scan from hell(http://sqlblog.com/blogs/hugo_kornelis/archive/2006/11/03/The-table-scan-from-hell.aspx)
Versions etc.
This script was written and tested on SQL Server 2012. It should also work on 2008 and 2008 R2.
See comment block in procedure source code for version history of the procedure.
Copyright © 2026 DataRecoup Recovery Services. All Rights Reserved. Designed by DataRecoup Lab.
